Einführung
Vor einiger Zeit habe ich auf Twitter gelesen, dass Roy Osherove sich mit Build Patterns auseinander setzt und ein entsprechendes Buch („Beautiful Builds“) darüber schreiben will. Da es bei LeanPub veröffentlich wird, kann man es bereits vor der Fertigstellung kaufen und reinlesen:
Im Rahmen der Konferenz „Continuous Lifecycle 2013“ am 12.11.2013 in Karlsruhe werde ich ebenfalls einen Kurz-Vortrag zu diesem Thema halten.
Zur Vertiefung möchte ich an dieser Stelle einige Patterns mit Beispielen vorstellen. Den Anfang macht das Pattern „Build Script Injection“.
Problembeschreibung
Roy Osherove hat in seinem Blogbeitrag „Build Patterns: Script Injection“ bereits das Problem beschrieben:
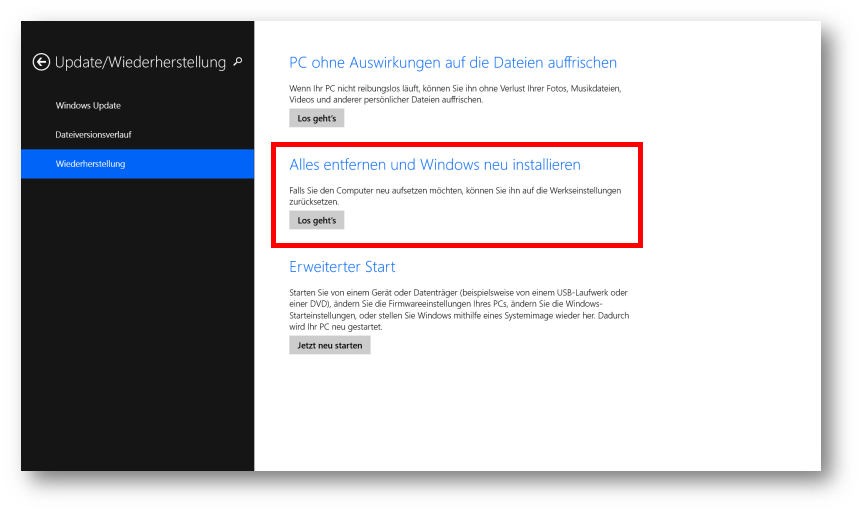
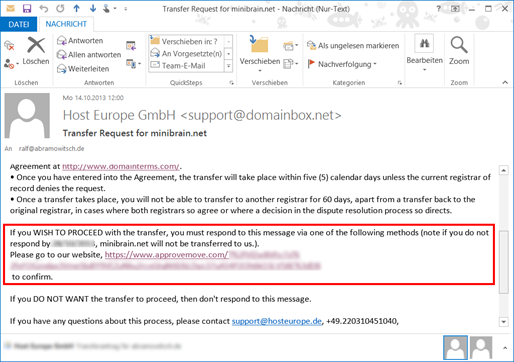
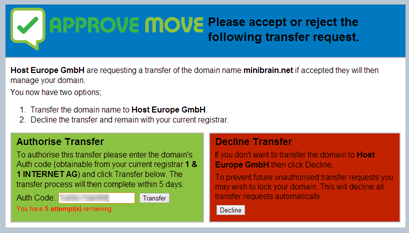
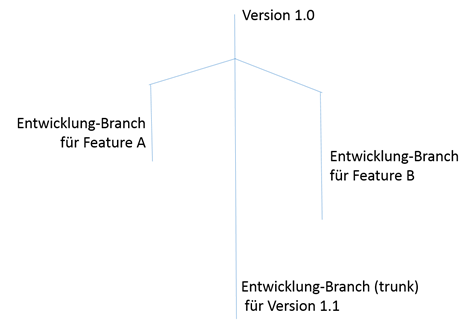
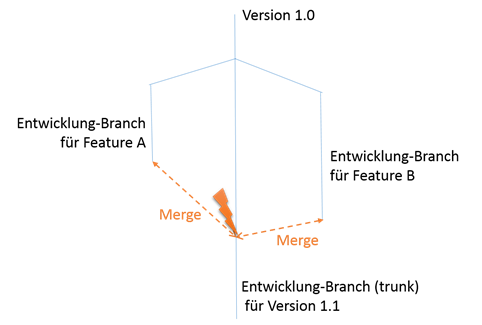
Man hat einen Continuous Integration Prozess etabliert, Quellcode wird aus der Versionsverwaltung ausgecheckt, gebaut und Tests ausgeführt. Über die Zeit und Versionen haben sich jedoch die Ordnerstruktur und/oder Build-Schritte geändert:
|
Projektstruktur zu Zeitpunkt A
|
Projektstruktur zu Zeitpunkt B (Produktversion 2.0)
|
Soweit so gut. Aktuelle Versionen können jederzeit gebaut werden. Doch was ist, wenn plötzlich ein Patch für Produktversion 1.0 gebaut werden muss? Die Build-Konfiguration greift dann auf Ordner zu, die es früher gar nicht gab und der Build funktioniert nicht mehr.
Lösungsansatz
Um das Problem lösen zu können, muss man den statischen Anteil der Build-Konfiguration vom dynamischen Anteil der Build-Konfiguration trennen. Den dynamischen Anteil lagert man in ein Build-Skript aus, das unter Versionskontrolle steht und versionsabhängig modifiziert werden kann.
Ausgangssituation
Zu Beginn enthält die Build-Konfiguration alle Logik über den Buildablauf und Zugriff auf die Ordner-Strukturen:
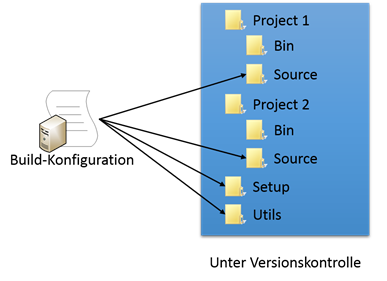
Ändert sich die Verzeichnisstruktur oder ein Build-Step, dann ist die Build-Konfiguration nicht mehr „rückwärtskompatibel“. Möchte man ältere Versionen wieder bauen, muss die gesamte Build-Konfiguration entweder angepasst oder eine Kopie pro Version angelegt werden. Das führt jedoch auf Dauer zu einer sehr großen Varianz und wird schlecht wartbar sein.
Zielsituation
Die Build-Konfiguration wird aufgesplittet und einen dynamischen und statischen Anteil:
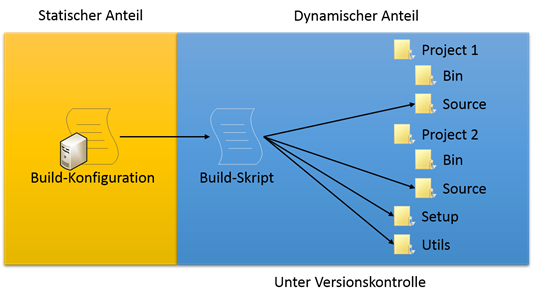
Der statische Anteil befindet sich in der Build-Konfiguration auf dem CI-Server. Der dynamische Anteil wird in ein Build-Skript ausgelagert. Das Build-Skript enthält die gesamte Build-Logik als auch Informationen über die Verzeichnisstruktur. Zudem unterliegt das Build-Skript nun der Versionskontrolle. Dadurch dass die Build-Konfiguration auf dem CI-Server nur noch das Build-Skript aufruft, können Abläufe beliebig ausgetauscht werden, ohne dass der Build kaputt geht.