Die Merge-Hölle
Bei der professionellen Software-Entwicklung ist eine Versionsverwaltung nicht mehr wegzudenken. Fast alle Versionskontroll-Systeme unterstützen Branches, in denen man beispielsweise die Entwicklung von Features vornimmt, um den Code im Hauptzweig (trunk) nicht zu beeinflussen und unabhängig das Feature entwickeln zu können:
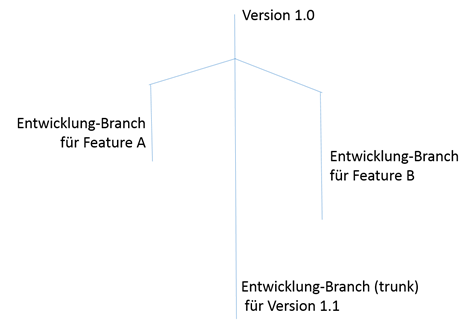
Hier ist ein Beispiel dafür, wie ich bisher die Produkt- / Projektentwicklung kannte: Nachdem eine Produkt-Version released wurde, werden Feature-Branches angelegt, um die Features unabhängig vom Entwicklungs-Branch zu entwickeln. Das hat sehr viele Vorteile: Beispielsweise könnte sich das Produktmanagement entscheiden, ein Feature erst in einer späteren Version zu integrieren, falls sich die Entwicklung verzögern sollte. Zudem kann die Entwicklung eines Features unabhängig von der Entwicklung anderer Features stattfinden.
Wer so arbeitet, kennt auch den Begriff der „Merge-Hölle“. Diese tritt nämlich dann auf, wenn die Entwicklungs-Branches für unterschiedliche Features und der trunk im Code zu weit auseinander laufen oder Code in der gleichen Datei mehrfach umgebaut wurde. Dann nämlich funktioniert der Merge nicht mehr so einfach:
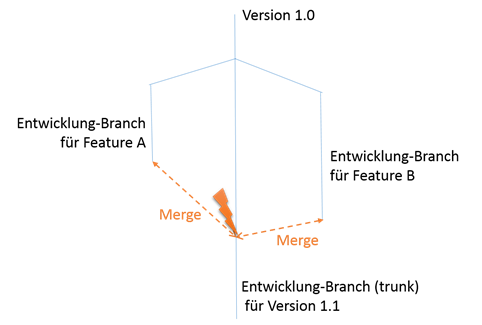
Wenn es sich dabei nur um eine Code-Datei handelt, ist das zwar ärgerlich, aber noch akzeptabel. Die Merge-Hölle ergibt sich, wenn sehr viele Dateien in unterschiedlichen Entwicklungszweigen verändert wurden und vielleicht sogar noch neue Dateien mit gleichem Namen angelegt wurden. Dann funktioniert in der Regel der Merge nicht mehr und man verbringt Stunden und Tage damit, die Konflikte aufzulösen und hofft, dass danach noch alles so funktioniert, wie es man gedacht war.
Weiterhin kann es passieren, dass Probleme, die in einem Branch gefixt wurden, durch den Merge wieder verloren gehen.
Das Feature Toggle Pattern
Hier kann das Feature-Toggle-Pattern Abhilfe schaffen:
Anstelle der Verwendung unterschiedlicher Entwicklungs-Branches findet sie Entwicklung immer auf dem gleichen Branch (trunk) statt. Martin Fowler hat in seinem Artikel „Feature Toggle“ (http://martinfowler.com/bliki/FeatureToggle.html) detailliert beschrieben, wie das Feature-Toggle Pattern funktioniert.
Damit ist es möglich, auch noch „experimentellen“, noch nicht fertigen Code in Produktivsystemen zu releasen. Man muss quasi nur sicherstellen, dass der unfertige Code nie ausgeführt wird. Dadurch arbeitet jeder immer auf dem aktuellen Entwicklungszweig und kann Änderungen an der Codebasis registrieren und darauf reagieren.
Doch wie setzt man das Feature Toggle Pattern in der Praxis um?
Wichtig ist, dass die Stelle, an der das Feature aktiviert bzw. deaktiviert wird, später einfach zu finden und zu entfernen ist, wenn das Feature „produktiv“ geschaltet wird. Wenn ein Schalter nicht entfernt wird, bürdet man sich unnötigerweise „technische Schulden“ auf. Am einfachsten geht das beispielsweise mit einer (abstrakten) Klasse, die eine Property „IsEnabled“ zur Verfügung stellt und von der alle Feature Schalter erben:
internal
abstract
class
FeatureSwitch
{
public
abstract
bool
IsEnabled { get; set; }
}
Von dieser Klasse FeatureSwitch leitet man nun einfach einen Schalter für das eigene Feature („MyFeature“) ab:
internal
class
MyFeatureSwitch : FeatureSwitch
{
private
bool
_isEnabled = true;
public
override
bool
IsEnabled
{
get { return
_isEnabled; }
set { _isEnabled = value; }
}
}
Hier wird das Feature by-default eingeschaltet (_inEnabled = true). Genauso einfach kann das Feature auch wieder deaktiviert werden.
Im Code verwendet man den Schalter dann so:
MyFeatureSwitch myFeature = new
MyFeatureSwitch();
if (myFeature.IsEnabled)
{
// implement feature code here …
}
else
{
}
Man instanziiert einfach an einer beliebigen Stelle, an der das Feature verwendet wird, den FeatureSwitch. Dort prüft man dann über die Eigenschaft „IsEnabled“, ob das Feature „scharf geschaltet“ ist und implementiert den Code so, als wenn das Feature produktiv verwendet wird.
Alternativ zur abstrakten Basisklasse „FeatureSwitch“ könnte man auch einen ConfigSwitch verwenden wie ich es beispielsweise im Blog von Federik Normen gesehen habe: http://weblogs.asp.net/fredriknormen/archive/2013/09/28/merge-hell-and-feature-toggle.aspx